Edit : Just a couple of days after this post, OpenAI released a speech recognition model called Whisper, which is so much better than anything I’ve ever seen before. I’ve decided to leave this post as it is, but check the Emacs config for the updated version.
In my experience, finding something in a podcast is particularly troublesome. For example, occasionally I want to refer to some line in the podcast to make an org-roam node, e.g. I want to check that I got that part right.
And I have no reasonable way to get there because audio files in themselves don’t allow for random access, i.e. there are no “landmarks” that point to this or that portion of the file. At least if nothing like a transcript is available.
For obvious reasons, podcasts rarely ship with transcripts. So in this post, I’ll be using a speech recognition engine to make up for that. A generated transcript is not quite as good as a manually written one, but for the purpose of finding a fragment of a known podcast, it works well enough.
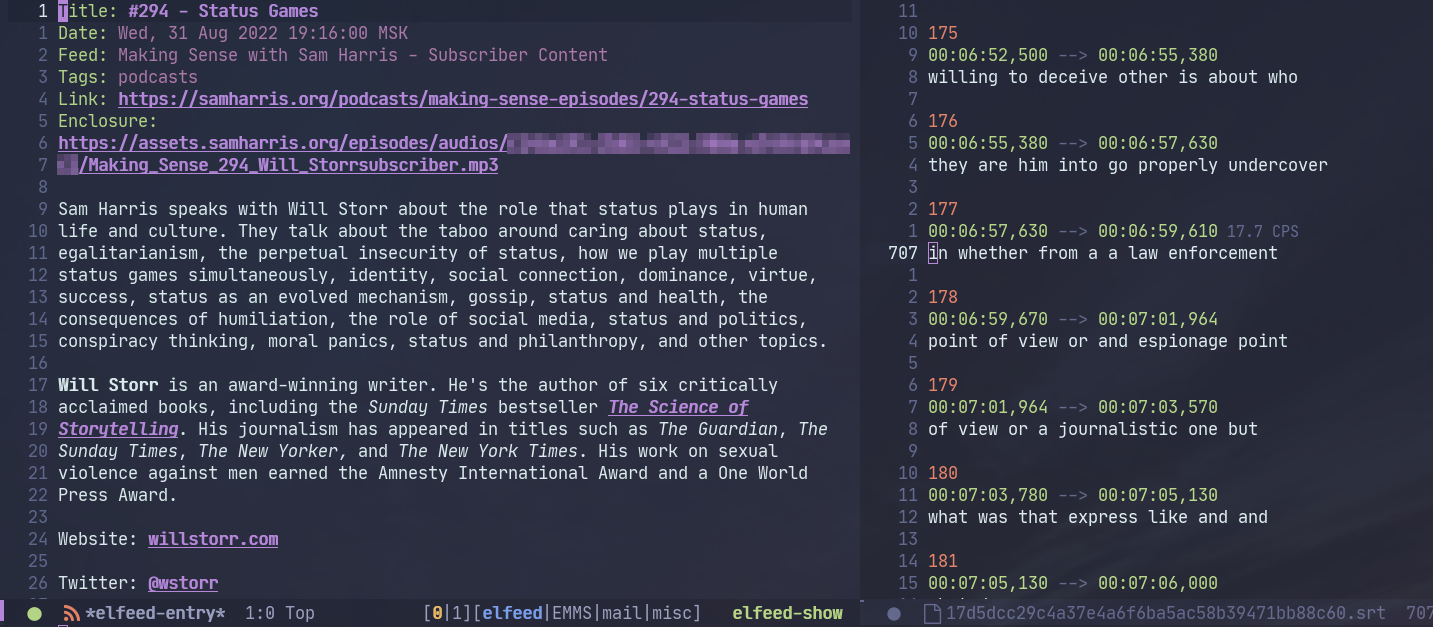
The general idea is to get the podcast info from elfeed, process it with vosk-api and feed it to subed to control the playback in MPV. I’ve done something similar for YouTube videos in the previous post, by the way.
Be sure to enable lexical binding for the context of evaluation. For instance, for init.el you can add the following line to the top:
;;; -*- lexical-binding: t -*-
Vosk API
After some search, I found Vosk API, an offline speech recognition toolkit.
I want to make a program that receives an audio file and outputs an SRT file. Vosk provides bindings to different languages, of which I choose Python because… reasons.
So, with the help of kindly provided examples of how to use the Python API, the resulting script is listed below. Except Vosk, the script uses click to make a simple CLI, a library aptly called srt to make srt files, and ffmpeg.
import datetime
import json
import math
import subprocess
import click
import srt
from vosk import KaldiRecognizer, Model, SetLogLevel
@click.command()
@click.option('--file-path', required=True, help='Path to the audio file')
@click.option('--model-path', required=True, help='Path to the model')
@click.option(
'--save-path',
required=True,
default='result.srt',
help='Path to resulting SRT file'
)
@click.option(
'--words-per-line',
required=True,
type=int,
default=14,
help='Number of words per line'
)
def transcribe(file_path, model_path, save_path, words_per_line=7):
sample_rate = 16000
SetLogLevel(-1)
model = Model(model_path)
rec = KaldiRecognizer(model, sample_rate)
rec.SetWords(True)
process = subprocess.Popen(
[
'ffmpeg', '-loglevel', 'quiet', '-i', file_path, '-ar',
str(sample_rate), '-ac', '1', '-f', 's16le', '-'
],
stdout=subprocess.PIPE
)
results = []
while True:
data = process.stdout.read(4000)
if len(data) == 0:
break
if rec.AcceptWaveform(data):
res = json.loads(rec.Result())
results.append(res)
if math.log2(len(results)) % 2 == 0:
print(f'Progress: {len(results)}')
results.append(json.loads(rec.FinalResult()))
subs = []
for res in results:
if not 'result' in res:
continue
words = res['result']
for j in range(0, len(words), words_per_line):
line = words[j:j + words_per_line]
s = srt.Subtitle(
index=len(subs),
content=" ".join([l['word'] for l in line]),
start=datetime.timedelta(seconds=line[0]['start']),
end=datetime.timedelta(seconds=line[-1]['end'])
)
subs.append(s)
srt_res = srt.compose(subs)
with open(save_path, 'w') as f:
f.write(srt_res)
if __name__ == '__main__':
transcribe()
Here’s the corresponding requirements.txt:
vosk
click
srt
Another piece we need is a speech recognition model, some of which you can download on their website. I chose a small English model called vosk-model-small-en-us-0.15 because all my podcasts are in English and also because larger models are much slower.
Now that we have the script and the model, we need to create a virtual environment. Somehow I couldn’t install the vosk package with conda, but the Guix version of Python with virtualenv worked just fine:
python3 -m virtualenv venv
source venv/bin/activate
pip install -r requirements.txt
After which the script can be used as follows:
python main.py --file-path <path-to-file> --model-path ./model-small --save-path <path-to-subtitles-file>.srt
Running it from Emacs
The next step is to run the script from Emacs. This is rather straightforward to do with asyncronous processes.
(defvar my/vosk-script-path
"/home/pavel/Code/system-crafting/podcasts-vosk/"
"Path to the `podcasts-vosk' script folder.")
(defun my/invoke-vosk (input output)
"Extract subtitles from the audio file.
INPUT is the audio file, OUTPUT is the path to the resulting SRT file."
(interactive
(list
(read-file-name "Input file: " nil nil t)
(read-file-name "SRT file: ")))
(let* ((buffer (generate-new-buffer "vosk"))
(default-directory my/vosk-script-path)
(proc (start-process
"vosk_api" buffer
(concat my/vosk-script-path "venv/bin/python")
"main.py" "--file-path" input "--model-path" "./model-small"
"--save-path" output "--words-per-line" "14")))
(set-process-sentinel
proc
(lambda (process _msg)
(let ((status (process-status process))
(code (process-exit-status process)))
(cond ((and (eq status 'exit) (= code 0))
(notifications-notify :body "SRT conversion completed"
:title "Vosk API"))
((or (and (eq status 'exit) (> code 0))
(eq status 'signal))
(let ((err (with-current-buffer (process-buffer process)
(buffer-string))))
(kill-buffer (process-buffer process))
(user-error "Error in Vosk API: %s" err)))))))))
If run interactively, the defined function prompts for paths to both files.
The process sentinel sends a desktop notification because it’s a bit more noticeable than message, and the process is expected to take some time.
Integrating with elfeed
To actually run the function from the section above, we need to download the file in question.
So first, let’s extract the file name from the URL:
(defun my/get-file-name-from-url (url)
"Extract file name from the URL."
(string-match (rx "/" (+ (not "/")) (? "/") eos) url)
(let ((match (match-string 0 url)))
(unless match
(user-error "No file name found. Somehow"))
;; Remove the first /
(setq match (substring match 1))
;; Remove the trailing /
(when (string-match-p (rx "/" eos) match)
(setq match (substring match 0 (1- (length match)))))
match))
I use a library called request.el to download files elsewhere, so I’ll re-use it here. You can just as well invoke curl or wget via a asynchronous process.
This function downloads the file to a non-temporary folder, which is ~/.elfeed/podcast-files/ if you didn’t move the elfeed database. That is so because a permanently downloaded file works better for the next section.
(with-eval-after-load 'elfeed
(defvar my/elfeed-vosk-podcast-files-directory
(concat elfeed-db-directory "/podcast-files/")))
(defun my/elfeed-vosk-get-transcript-new (url srt-path)
(let* ((file-name (my/get-file-name-from-url url))
(file-path (expand-file-name
(concat
my/elfeed-vosk-podcast-files-directory
file-name))))
(message "Download started")
(unless (file-exists-p my/elfeed-vosk-podcast-files-directory)
(mkdir my/elfeed-vosk-podcast-files-directory))
(request url
:type "GET"
:encoding 'binary
:complete
(cl-function
(lambda (&key data &allow-other-keys)
(let ((coding-system-for-write 'binary)
(write-region-annotate-functions nil)
(write-region-post-annotation-function nil))
(write-region data nil file-path nil :silent))
(message "Conversion started")
(my/invoke-vosk file-path srt-path)))
:error
(cl-function
(lambda (&key error-thrown &allow-other-keys)
(message "Error!: %S" error-thrown))))))
I also experimented with a bunch of options to write binary data in Emacs, of which the way with write-region (as implemented in f.el) seems to be the fastest. This thread on StackExchange suggests that it may screw some bytes towards the end, but whether or not this is the case, mp3 files survive the procedure. The proposed solution with seq-doseq takes at least a few seconds.
Finally, we need a function to show the transcript if it exists or invoke my/elfeed-vosk-get-transcript-new if it doesn’t. And this is the function that we’ll call from an elfeed-entry buffer.
(defun my/elfeed-vosk-get-transcript (entry)
"Retrieve transcript for the enclosure of the current elfeed ENTRY."
(interactive (list elfeed-show-entry))
(let ((enclosure (caar (elfeed-entry-enclosures entry))))
(unless enclosure
(user-error "No enclosure found!"))
(let ((srt-path (concat my/elfeed-srt-dir
(elfeed-ref-id (elfeed-entry-content entry))
".srt")))
(if (file-exists-p srt-path)
(let ((buffer (find-file-other-window srt-path)))
(with-current-buffer buffer
(setq-local elfeed-show-entry entry)))
(my/elfeed-vosk-get-transcript-new enclosure srt-path)))))
Integrating with subed
Now that we’ve produced a .srt file, we can use a package called subed to control the playback, like I had done in the previous post.
By the way, this wasn’t the most straightforward thing to figure out, because the MPV window doesn’t show up for an audio file, and the player itself starts in the paused state. So I thought nothing was happening until I enabled the debug log.
With that in mind, here’s a function to launch MPV from the buffer generated by my/elfeed-vosk-get-transcript:
(defun my/elfeed-vosk-subed (entry)
"Run MPV for the current Vosk-generated subtitles file.
ENTRY is an instance of `elfeed-entry'."
(interactive (list elfeed-show-entry))
(unless entry
(user-error "No entry!"))
(unless (derived-mode-p 'subed-mode)
(user-error "Not subed mode!"))
(setq-local subed-mpv-video-file
(expand-file-name
(concat my/elfeed-vosk-podcast-files-directory
(my/get-file-name-from-url
(caar (elfeed-entry-enclosures entry))))))
(subed-mpv--play subed-mpv-video-file))
After running M-x my/elfeed-vosk-subed, run M-x subed-toggle-loop-over-current-subtitle (C-c C-l), because somehow it’s turned on by default, and M-x subed-toggle-pause-while-typing (C-c C-p), because sometimes this made my instance of MPV lag.
After that, M-x subed-mpv-toggle-pause should start the playback, which you can control by moving the cursor in the buffer.
You can also run M-x subed-toggle-sync-point-to-player (C-c .) to toggle syncing the point in the buffer to the currently played subtitle (this automatically gets disabled when you switch buffers).
Running M-x subed-toggle-sync-player-to-point (C-c ,) does the opposite, i.e. sets the player position to the subtitle under point. These two functions are useful since the MPV window controls aren’t available.
Some observations
So, the functions above work for my purposes.
I think it should be possible to get transcripts of better quality by using a better speech recognition model, adding a speaker detection model and a model to restore case & punctuation. But it seems to be harder to implement, and this would take more time and resources. On my PC, the smallest Vosk model runs maybe 10 times faster than the playback time, which is still a few minutes for an hour-long podcast. Waiting longer is probably not worth it.
Also, technically MPV can stream files without downloading them, and it’s even possible to feed stream data into Vosk. But MPV isn’t particularly good at seeking in streamed files, at least not with my Internet connection.